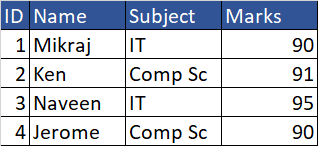
Structured Data
When data is stored in the form of tables and tables contain rows and columns.For example, If you store the data in any DBMS or RDBMS then it is structured data.
Student table:
Fields ID,Name,Subject,Marks
Records : 4 records
UnStrcutred Data
When data is not get stored in the form of RDBMS then it is unstructured data for example images.
SemiStructred Data
Semi-structured data is a form of structured data that does not obey the tabular structure of data models associated with relational databases or other forms of data tables, but nonetheless contains tags or other markers to separate semantic elements and enforce hierarchies of records and fields within the data. Therefore, it is also known as self-describing structure.
Example Json,XML
NoSql
A NoSQL (originally referring to “non-SQL” or “non-relational”) database provides a mechanism for storage and retrieval of data that is modeled in means other than the tabular relations used in relational databases.
Examples MongoDB, DyanmoDB in AWS
Amazon DynamoDB
Fast, flexible NoSQL database service for single-digit millisecond performance at any scale
DynamoDB maintaining administrative tasks of operating and scaling a distributed database
DynamoDB handles hardware provisioning, setup, and configuration, replication, software patching, or cluster scaling.
DynamoDB also offers encryption at rest, to protect sensitive data.
Serverless:-With DynamoDB, there are no servers to provision, patch, or manage, and no software to install, maintain or operate. DynamoDB automatically scales tables to adjust for capacity and maintains performance with zero administration. Availability and fault tolerance are built-in, eliminating the need to architect your applications for these capabilities.
Fast, flexible NoSQL database service for single-digit millisecond performance at any scale
DynamoDB global tables replicate your data automatically across your choice of AWS Regions and automatically scale capacity to accommodate your workloads.
Read/write capacity modes
On-Demand Capacity mode
For workloads that are less predictable for which you are unsure that you will have high utilization.
Provisioned Capacity mode
Tables using provisioned capacity mode require you to set read and write capacity. Provisioned capacity mode is more cost effective when you’re confident you’ll have decent utilization of the provisioned capacity you specify.
Autoscaling
For tables using provisioned capacity, DynamoDB delivers automatic scaling of throughput and storage based on your previously set capacity by monitoring the performance usage of your application
Change tracking with triggers
DynamoDB integrates with AWS Lambda to provide triggers. Using triggers, you can automatically execute a custom function when item-level changes in a DynamoDB table are detected.
Table Class
Table class to optimize your table’s cost based on your workload requirements and data access patterns.
DynamoDB Standard
The default general-purpose table class. Recommended for the vast majority of tables that store frequently accessed data, with throughput (reads and writes) as the dominant table cost.
Lab:- Create a DynamoDB Student Table with some records, then scan the table and query on the table.
Step 1: Search Dynamodb service
Step 2: Select Table and Click on Create Table and Provide below information
Table Name: Student
Partition key: Id Data type: Number
Sort Key: Name Data type: String
Settings: Default Settings
Click on Create table button.
Step 3: The table should be created and in Active State.
Step 4: Click on Student Table
Step 5: Goto Action—> Create item
Step 6: You can create item using Form or Writing JSON
Step 7: Repeat Step 5 and 6 to add more items
Step 8: After adding multiple records click on Explore items
Step 9: Select Scan Tab and Click on the Run button it will show all the records.
Step 10: Select Query Tab and Search on the basis of Partition key and other attribute values. Structured Data
When data is stored in the form of tables and tables contain rows and columns.For example, If you store the data in any DBMS or RDBMS then it is structured data.
Student table:
Fields ID,Name,Subject,Marks
Records : 4 records
UnStrcutred Data
When data is not get stored in the form of RDBMS then it is unstructured data for example images.
SemiStructred Data
Semi-structured data is a form of structured data that does not obey the tabular structure of data models associated with relational databases or other forms of data tables, but nonetheless contains tags or other markers to separate semantic elements and enforce hierarchies of records and fields within the data. Therefore, it is also known as self-describing structure.
Example Json,XML
NoSql
A NoSQL (originally referring to “non-SQL” or “non-relational”) database provides a mechanism for storage and retrieval of data that is modeled in means other than the tabular relations used in relational databases.
Examples MongoDB, DyanmoDB in AWS
Amazon DynamoDB
Fast, flexible NoSQL database service for single-digit millisecond performance at any scale
DynamoDB maintaining administrative tasks of operating and scaling a distributed database
DynamoDB handles hardware provisioning, setup, and configuration, replication, software patching, or cluster scaling.
DynamoDB also offers encryption at rest, to protect sensitive data.
Serverless:-With DynamoDB, there are no servers to provision, patch, or manage, and no software to install, maintain or operate. DynamoDB automatically scales tables to adjust for capacity and maintains performance with zero administration. Availability and fault tolerance are built-in, eliminating the need to architect your applications for these capabilities.
Fast, flexible NoSQL database service for single-digit millisecond performance at any scale
DynamoDB global tables replicate your data automatically across your choice of AWS Regions and automatically scale capacity to accommodate your workloads.
Read/write capacity modes
On-Demand Capacity mode
For workloads that are less predictable for which you are unsure that you will have high utilization.
Provisioned Capacity mode
Tables using provisioned capacity mode require you to set read and write capacity. Provisioned capacity mode is more cost effective when you’re confident you’ll have decent utilization of the provisioned capacity you specify.
Autoscaling
For tables using provisioned capacity, DynamoDB delivers automatic scaling of throughput and storage based on your previously set capacity by monitoring the performance usage of your application
Change tracking with triggers
DynamoDB integrates with AWS Lambda to provide triggers. Using triggers, you can automatically execute a custom function when item-level changes in a DynamoDB table are detected.
Table Class
Table class to optimize your table’s cost based on your workload requirements and data access patterns.
DynamoDB Standard
The default general-purpose table class. Recommended for the vast majority of tables that store frequently accessed data, with throughput (reads and writes) as the dominant table cost.
Lab:- Create a DynamoDB Student Table with some records, then scan the table and query on the table.
Step 1: Search Dynamodb service
Step 2: Select Table and Click on Create Table and Provide below information
Table Name: Student
Partition key: Id Data type: Number
Sort Key: Name Data type: String
Settings: Default Settings
Click on Create table button.
Step 3: The table should be created and in Active State.
Step 4: Click on Student Table
Step 5: Goto Action—> Create item
Step 6: You can create item using Form or Writing JSON
Step 7: Repeat Step 5 and 6 to add more items
Step 8: After adding multiple records click on Explore items
Step 9: Select Scan Tab and Click on the Run button it will show all the records.
Step 10: Select Query Tab and Search on the basis of Partition key and other attribute values.
